

1.1數據采集子系統
利用互聯網爬蟲、公開數據服務接口、動態網站采集與解析、元搜索引擎相結合的方式,采集國際主流與指定國家或地區的區域性主流社交網絡媒體、搜索引擎、新聞網站、論壇、博客等平臺的公開數據。自動下載與特定賬號或特定關鍵詞相關的全量數據(包括文本、圖像、視頻、屬性、關聯信息等)并存儲,用于后續分析溯源。
1.1.1搜索引擎采集
1) Baidu/文字
2) Google/文字、圖像、視頻
3) Bing/文字、圖像
4) Naver/文字、視頻
1.1.2 Twitter數據采集
1)用戶信息采集
用戶頭像URL、用戶ID、用戶名稱、用戶昵稱、用戶描述、用戶位置、賬號創建時間、關注人數、粉絲人數、發布推文數量、最近發文時間等。
2)發布內容信息采集
推文信息:推文url、發帖作者、推文類型(文字、圖片、視頻)、推文內容、推文發布時間,是否原創、原創作者ID、點贊數、評論數、轉發數以及相對應的用戶列表;
詳細信息:點贊用戶ID;評論用戶ID、評論內容、評論時間;轉發用戶ID、轉發內容、分享時間等。
1.1.3 Youtube數據采集
支持頻道(專欄)信息、視頻標題、描述、發布時間、視頻內容、評論等數據采集;支持實時監測指定視頻網站點擊率,一旦發現某時間內點擊率上升最快或點擊率最高的視頻,立即下載。
1.1.4 LinkedIn數據采集
支持用戶賬號簡歷全量信息及動態發布信息采集,組織或單位成員簡歷全量信息及動態發布信息采集。
具體采集內容包括:頭像、用戶名、現居地、個人介紹、現任職務、工作地點、畢業院校、聯系方式、好友數量;工作經歷:入職時間、離職時間、公司名稱、職位;學習經歷:入學時間、畢業時間、學校、專業、學位;參與項目信息、資格認證、技能認可、語言能力等。
1.1.5 Instagram數據采集
支持用戶個人信息,關注好友信息,發布內容(圖片、視頻),發布時間等信息的采集。
1.2數據清洗子系統
對采集到的冗雜數據進行數據清洗,過濾掉相同和相似數據,提高系統吞吐量;針對去冗余后的圖像視頻數據,首先對其進行轉碼,將其轉化為系統可處理的格式,然后對視頻進行關鍵幀抽取,將大段視頻轉化為可代表其主要內容一定數量的圖像幀,便于下一步的識別分析。
模塊技術方案圖如下圖所示。核心算法包括兩部分:圖像特征/指紋提取及引擎檢測識別。
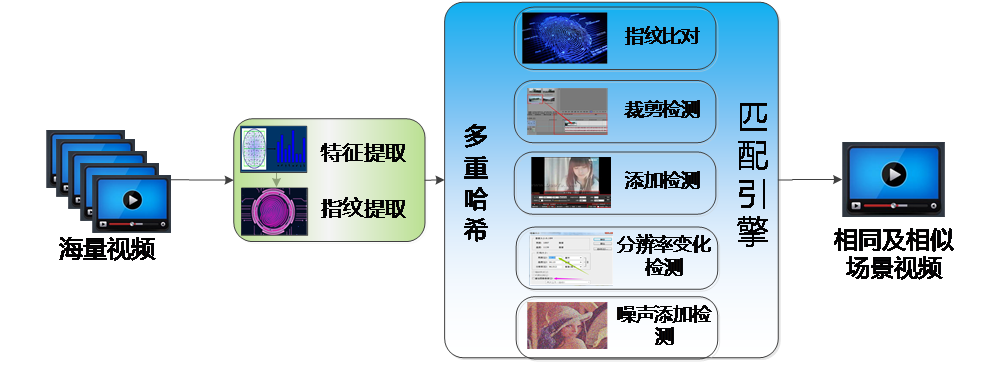
圖1 視頻/圖像預處理流程圖
基于哈希的視頻特征/指紋提取,針對視頻文件,本模塊設計基于強哈希、模糊哈希和感知哈希的圖像特征、指紋提取算法。
基于強哈希的圖像指紋提取算法,對于任意輸入視頻,通過MD5算法產生該視頻的指紋。計算指紋時面對的輸入視頻數據,由于視頻數據因其時長不一,體積可能達到任意大小。因此,若在計算指紋時對所有文件都將其整體作為輸入,可能在遇到較大視頻時占用很多計算資源,同時影響指紋計算的速度。因此,在實現過程中配置了自適應的指紋生成策略:
1) 對于體積小于閾值的視頻數據,則將其整體作為輸入進行計算,生成MD5指紋信息;
2) 對于體積大于閾值的視頻數據,則取其文件前4096 bits、中4096 bits和尾部4096 bits組合成新的數據,將其作為輸入進行計算,生成MD5指紋信息。
基于模糊哈希的特征、指紋提取算法,模糊哈希特征通過分片技術解決傳統哈希算法無法處理文件改動的弊端,可用于識別經裁剪、添加后的BK場景圖像信息。算法采取四個環節實現特征指紋提取,首先基于Alder-32以及一個分片值實現弱哈希算法,用于文件分片;然后基于Fowler-Noll-Vo hash實現強哈希算法,計算每片哈希值,完成特征提取;最后實現基于FNV哈希算法實現特征壓縮映射,完成指紋提取。
基于感知哈希的特征、指紋提取算法,感知哈希特征對圖像的尺寸變換,噪聲變換具有較強適應性,可用于識別經分辨率變化、噪聲變化的BK場面圖像信息。算法首先通過尺度縮小、色彩簡化最快速去除圖像高頻細節,摒棄不同尺寸及顏色微變帶來的圖片差異,然后基于離散余弦變換、低頻采樣提取圖片中的低頻信息,去除高頻噪聲信息的干擾,完成特征提取;最后基于特征均值激活方法將特征映射為64bit的長整形指紋,完成指紋提取。
完成指紋提取后,設計指紋匹配策略如下:
針對強哈希指紋信息,將待測文件MD5值輸入已有文件庫中進行檢索,如果發現完全相同的MD5值,即發現目標文件。
針對模糊哈希指紋信息,基于加權編輯距離實現匹配檢測功能。加權編輯距離計算將待匹配的兩個字符串(指紋)信息變成相同指紋最少需要多少步操作(包括插入、刪除、修改、交換),然后對不同操作給出一個權值,將結果相加獲得加權編輯距離,算法然后將加權編輯局里除以兩個指紋的長度和,以將絕對結果變為相對結果,再映射到0-100的一個整數值上,其中,100表示兩個字符串完全一致,而0表示完全不相似,最后獲得相似程度的評分,當評分超過閾值,即發現目標文件。
針對感知哈希指紋信息,計算待匹配的兩個字符串(指紋)信息的漢明距離,然后基于漢明距離計算二者相似程度評分。當評分超過閾值,即發現目標文件。
1.3數據分析子系統
數據分析子系統通過數據融合等技術手段,實現對目標人物和目標事件的偵查,快速生成簡報或定制專業化報告。
1.3.1目標數據身份落地
針對目標數據進行跨平臺融合分析,同時將社交平臺中出現的人臉數據與監控視頻等非網絡數據中的圖像視頻人臉進行比對,從而將虛擬賬號與物理人對應起來,確定目標多重身份。人臉聚類的關鍵在于將眾多不明身份的人臉圖片進行身份分析,并將屬于同一身份的人臉圖片給予相同的身份ID。由于平臺圖片多不包含直接的身份信息,這里采用基于DBSCAN算法的無監督聚類的技術手段對人臉圖片進行聚類,能夠解決的已有聚類算法在人臉相似或者比較難分類的情況下,人臉聚類效果不好的問題。
具體步驟如下:
1) 首先進行人臉檢測和人臉特征提取。
2) 利用DBSCAN聚類算法對第(1)步提取的人臉特征進行初步聚類。DBSCAN聚類算法有兩個參數,分別為距離參數eps和形成高密度區域所需要的最少點數參數minPts。根據實際情況設置minPts參數,比如設置minPts=5,表示一個類中元素個數大于等于5個時,才會被認為是一個有效的類,否則就劃分為噪聲點。這一步的關鍵是距離參數eps的設定。這一步中需要將eps值設置小一些,使得聚類算法運行后得到的每一類的純度盡可能地高,即每一類盡可能都是同一個人的人臉圖片。
3) 對第(2)步得到的每一個類,計算類內兩兩人臉之間的距離,統計距離的中位數,若中位數值大于設定的閾值,則說明該類純度比較低,即類內包含多個人的人臉。此時需要用DBSCAN聚類算法進一步對該類再次聚類,再次聚類時eps參數需要設置更小,以便可以區分出不同人臉。對二次聚類產生的新的類,標記為難類;若中位數值小于設定的閾值,則說明該類純度高,類中為同一個人的人臉。對于沒有進行二次聚類的類,標記為普通類。
4) 對第(3)步得到的每一個類進行計算中心點。可以只計算每一個類中核心對象的中心點,使得計算出的中心點更加可靠。此處中心點的計算方式為計算每個類中人臉特征在各個維度上的算術平均值。
5) 遍歷目前還未被歸類的每一個人臉,計算該人臉與第(4)步得到的每一個中心點的距離,在這些距離中取出最小距離,若該最小距離大于設定的閾值,則仍將該點判斷為噪聲點,即不屬于第(4)步得到的任何一個類;若該最小距離小于設定的閾值,則將該點劃分到最小距離對應的類中。需要說明的是,對于難類和普通類,上述提到的閾值大小是不同的,難類對應的閾值要比普通類對應的閾值小,即劃分到難類的要求更高。
6) 根據第(5)步得到的類,重新計算每一個類的中心點。兩兩計算類中心點之間的距離,若距離小于設定的閾值,說明這兩個類的人臉屬于同一個人,則將這兩個類合并;若計算得到的距離大于設定的閾值,則說明這兩個類的人臉屬于不同人的人臉,不進行合并。需要說明的是,普通類與普通類的合并閾值要比難類參與的合并閾值要高一些,即難類參與的合并要求要高。
7) 如果待聚類的人臉數據非常多,那么直接聚類可能導致系統內存不足,因此可以考慮分批次聚類。具體做法為每次取一部分人臉數據按照上述步驟聚類,然后將每次的聚類結果合并到已有的類別上,合并規則為,比較新的類中心點與已有的類中心點之間的距離,若距離小于設定的閾值,則合并;否則就不合并,將該聚類結果保存為新的一個類。
至此完成了基于改進DBSCAN的人臉聚類方法。在人臉聚類后,每個人臉圖像都被賦予了一個身份ID,具有同一ID的圖像即為同一個人的人臉圖像。
1.3.2目標人物關系挖掘
針對目標數據進行跨平臺信息采集和融合分析,確定目標人物的身份信息、社交情況、政治傾向等信息,并建立目標區域重點人物數據庫。
要接近目標人物,通常需要從其身邊人入手,因此分析目標與其他人的通連關系意義重大,包括網絡空間人物通連關系和物理空間人物通連關系。其中,網絡空間人物通連關系指各社交平臺上目標人物賬號與其他賬號的相互關注關系、轉發關系、互動關系(點贊評論)等。可自動化爬取用戶的一度、二度、三度好友信息。
1.3.3特定事件偵查分析
可以快速采集指定地區主流網站、論壇、博客以及主流社交網站中的與目標事件相關的文字、圖像、視頻等信息素材,進行信息智能提取、關聯分析和綜合研判,針對目標事件在網絡上的整體傳播情況進行分析,找出傳播此信息的源頭和傳播路徑;采集網絡中出現的與該事件相關的圖像視頻信息,落地參與目標事件的人物信息。形成涵蓋目標事件簡介、熱點詞、參與人員、傳播途徑的特定目標數據分析報告。


